A Wroclaw Institute News Release
OAKLAND, Calif. — March 15, 2016 — We are pleased to inform that Wroclaw Institute has been appointed as a partner by Franz Inc.– world’s leading producer of semantic graph technologies. The agreement grants to Wroclaw Institute exclusive right to sell Franz’s – AllegroGraph family of products for territory of Poland. AllegroGraph is best in class graph database, fully supporting W3C standards adopted by start-up’s as well as vast number of Fortune 100 companies. AllegroGraph is a part of Big Data ecosystem as it could be integrated with Apache Hadoop and Amazon EC2.
The Wroclaw Institute CEO – Dr. Adam Iwaniak said “Partnership with Franz Inc. is a turning point for our company as semantic graph technology is gaining a lot of market attention in ‘data tsunami’ era. We are happy that we will be able to provide our customers with award winning solution to help them manage their complex data resources. Moreover I’d like to emphasize that as a company we made a big progress in leveraging RDF graphs technologies also on our basic market – geoinformatics”.
“We are excited about the opportunity to work with Dr. Iwaniak and the Wroclaw Institute team to demonstrate why Graph Databases deliver new, real time decision making capabilities for the Enterprise.” said Dr. Jans Aasman, CEO, Franz Inc., “Organizations across Poland will benefit from AllegroGraph’s ability to link highly complex data, generating new knowledge and insight for a significant competitive advantage.”
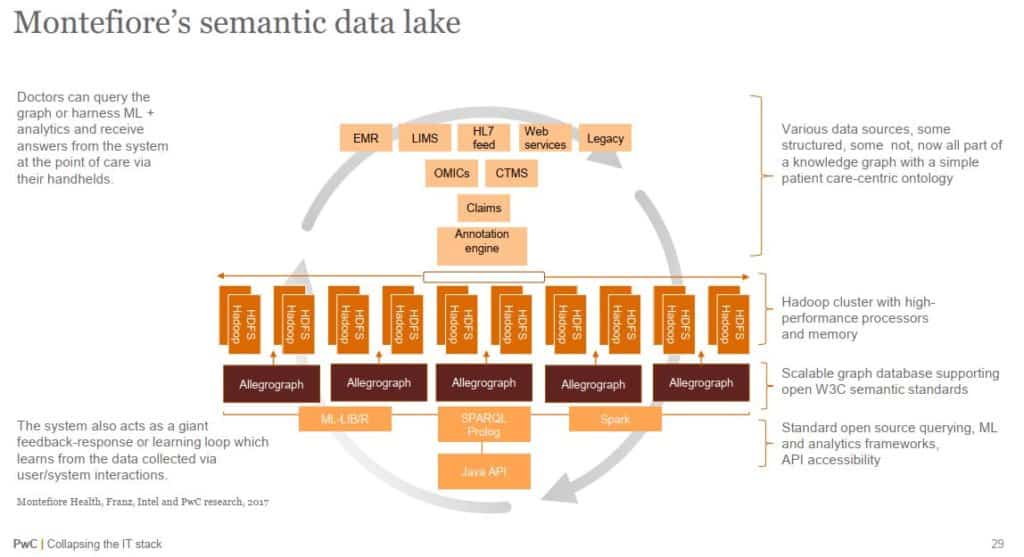
AllegroGraph is a database technology that enables businesses to extract sophisticated decision insights and predictive analytics from their highly complex, distributed data that can’t be answered with conventional databases. Unlike traditional relational databases, Franz’s product AllegroGraph employs a combination of semantic, graph and spatial technologies that process data with contextual and conceptual intelligence. AllegroGraph is able to run queries of unprecedented complexity to support predictive analytics that help companies make better, real-time decisions.
AllegroGraph is commonly used in defense and intelligence, banking, and insurance, pharmaceutical, and healthcare, Linked Data publishing, as well as by organization dealing with complex, constantly changing knowledge bases.
About Franz Inc.
Franz Inc. is a leading vendor of semantic technology tools featuring AllegroGraph – high-performance, scalable, disk-based graph database, provides the solid storage layer for powerful GeoTemporal Reasoning, Social Network Analytics and Ontology Modeling. Based in Oakland, California, Franz Inc. is an American owned company that delivers leading-edge development products that enable software developers to build flexible, scalable, semantic applications quickly and cost-effectively.
About The Wroclaw Institute
The Wroclaw Institute of Spatial Information and Artificial Intelligence is Wroclaw, Poland based technology company focused on knowledge engineering, data exploration and intelligent GIS providing products, services and solutions based on cutting-edge scientific and technological achievements.
Related Links
All trademarks and registered trademarks in this document are the properties of their respective owners.