Semantics at scale – Hadoop & AllegroGraph
Los Alamos National Labs - 99% name recongnition
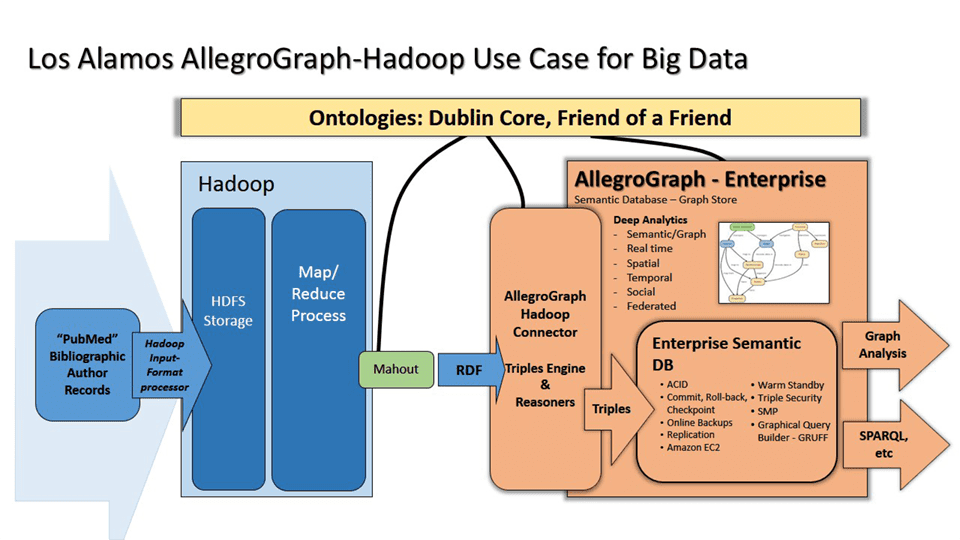
Los Alamos National Labs built a Big Data solution combining Hadoop and the AllegroGraph semantic graph platform to identify people, their social networks and connectedness across cultural and linguistic backgrounds.
The problem we are trying to solve cannot be solved with a Hadoop application alone…
– Los Alamos National Labs
Their Goal
Build a scalable application for processing terabytes of names and co-incident data using a demonstration dataset of structured and semi-structured bibliographic metadata to resolve authors, co-authors, all their associated publications, and shared affiliations.
Their Challenges
- A Big Data problem that cannot be solved with Hadoop alone
- Disambiguation of people’s names – for spelling variants, nick-names, misspellings, abbreviations
- Semi-structured data
- Scale to terabytes of content spanning multiple repositories and forms
- Uncover relationships not discoverable by traditional name matching
The Solution
Los Alamos were able to achieve a 99% accuracy in identifying and disambiguating people across terabyte size data sets.
Hadoop platform for:
- Large dataset processing
- Semi-structured data processing
- Economical scalability of data storage and processing
- Map-Reduce framework
- Creation of semantic triples
- Mahout machine learning platform for:
- Extraction of blocks of metadata from large XML fields
- Machine learning for field information
- Streaming input to Hadoop file system (HDFS)
- Map-Reduce framework
AllegroGraph Semantic Graph
- RDF, triple store and ontology platform
- Resolution of ambiguous names, abbreviations
- Identify affiliations/relationships
- Threshold-based matching of people relationships
- Analysis of connectedness, clusters of people and centrality
The Benefits

Enables sophisticated techniques to connect people and the information about them when names do not match exactly

System learns over time

Architecture scales to real world needs