
Benchmarks SP2
The SP2 benchmark comprises a data-generator for arbitrarily large documents, which builds upon the well-known DBLP scenario, and thus comes close to a real-world application scenario. The benchmark’s queries make meaningful requests against this data while also testing typical SPARQL operator constellations and RDF access patterns. With this focus, the benchmark can help tune existing SPARQL engines and detect deficiencies in them.
AllegroGraph’s SPARQL, one of the W3C’s “interoperable implementations”, includes a query optimizer, and has full support for named graphs. It can be used with the RDFS++ reasoning (i.e., query over real and inferred triples). SPARQL can be used with all the available AllegroGraph interfaces (Java, Python, Ruby, Perl, C#, Clojure, Lisp, etc).
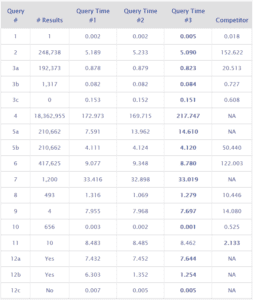
SP2 – 25 Million Dataset Results (Query Time in seconds)
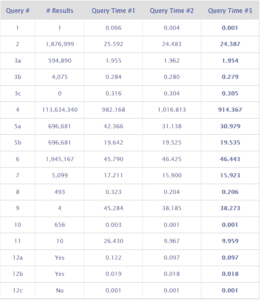
SP2 – 1 Million Dataset Results (Query Time in seconds)
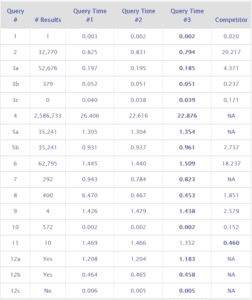
SP2 – 5 Million Dataset Results (Query Time in seconds)
The platform for the test was 2 – 4 core Intel E5520 Processors at 2.26 GHz, with 48 GB RAM, running Fedora 14.