- 14 March, 2024





Change Data Capture in AllegroGraph
The goal of Change Data Capture “CDC” is to manage incremental changes made in a source system, such as a relational database, and to update the integrated semantic master knowledge graph accordingly. This is important for design systems like Product Lifecycle Management systems, where changes to the database are made continuously. It would be very tedious to replace and relink the integrated master knowledge graph totally, every time a change to the source data occurs.
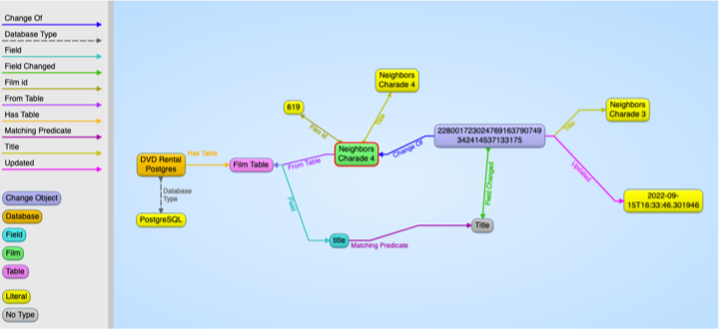
To facilitate incremental changes, the knowledge graph maintains a history of all changes and origins of individual graph objects, so that the system can trace back where in the RDB the change was made. If ontological rules are specified for the data, these changes can be SHACL (SHApe Constraint Language) validated incrementally.
For AllegroGraph projects, we use open-source tools, Kafka/Debezium, to stream in the change data in real-time to update the integrated master knowledge graph incrementally. We would generally process changes in batch, i.e., handle all recorded changes in one over-night session, allowing for day-time functionality to remain unaffected. All changes during the day are stored in a logging table within the source relational database. Data in the logging table is created by typical RDB trigger functions running on all tables, sending all updates to a single logging table.
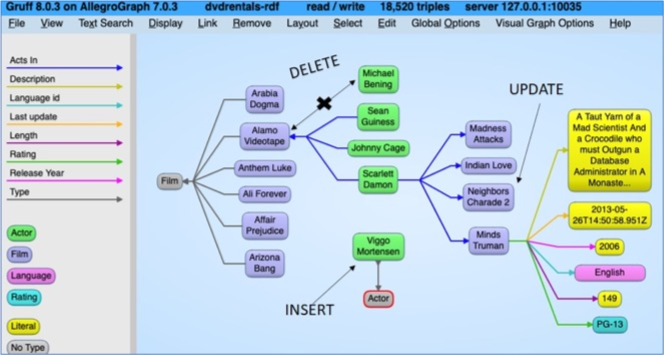
Here is a CDC methodology example using a movie database in PostgreSQL that consists of 4 tables –films, actors, languages, and film/actor links tables. We first ETL (Extract-Transform-Load) these 4 data tables to an RDF graph using semantic mapping tools.
We then make the following updates to the movie database:
§ INSERT INTO actor VALUES (204, ‘Viggo’, ‘Mortensen’, NOW());
§ DELETE FROM film_actor WHERE actor_id = 174 AND film_id = 11; § UPDATE film SET title = ‘Neighbors Charade 2’ WHERE film_id = 619
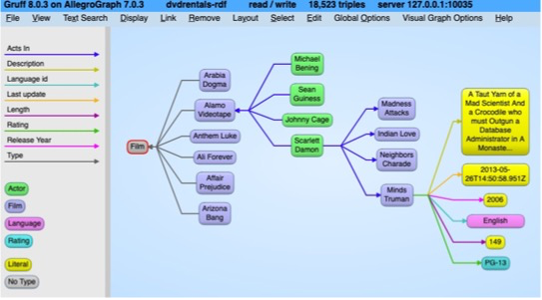
These updates are recorded in the logging table.

The system extracts these changes from the RDB logging table and update the RDF graph accordingly.
The RDF graph maintains a history of all changes and origins of individual objects in the PostgreSQL database. This history helps facilitate incremental changes easily.
What is Change Data Capture (CDC)?
CDC is a method of tracking and capturing changes (like inserts, updates, and deletes) made to a database, typically in a relational system (e.g., MySQL, PostgreSQL, SQL Server). This data is then moved to a target system for real-time analysis or integration.
Integration of CDC with AllegroGraph:
AllegroGraph, being a graph database, allows integration with other databases through its high-performance APIs. To leverage CDC with AllegroGraph, you’ll capture changes from the relational database and transform them into RDF (Resource Description Framework) triples to be stored and queried in AllegroGraph.
Here’s a step-by-step guide:
Step 1: Enable CDC in the Relational Database
Depending on the type of relational database, CDC may be enabled differently:
- MySQL: MySQL uses the binary log (binlog) to track changes. Tools like Debezium can capture binlog events for integration.
- PostgreSQL: Logical replication or tools like pg_logical can be used for capturing changes.
- SQL Server: SQL Server has built-in CDC functionality that tracks changes in tables.
Enable CDC on the tables you want to track. For instance, in SQL Server, you can enable CDC like this:
EXEC sys.sp_cdc_enable_table
@source_schema = N’dbo’,
@source_name = N’YourTable’,
@role_name = NULL;
Step 2: Extract Changes Using a CDC Tool
Use a tool or connector to extract these changes and stream them into a format suitable for AllegroGraph:
- Debezium: An open-source CDC tool that integrates well with Kafka. It listens to changes in your relational database and streams them.
- Kafka Connect: Kafka Connect (with Debezium) can act as a bridge between your relational database and AllegroGraph.
Example: Set up a Debezium connector for MySQL.
{
“name”: “mysql-connector”,
“config”: {
“connector.class”: “io.debezium.connector.mysql.MySqlConnector”,
“tasks.max”: “1”,
“database.hostname”: “localhost”,
“database.port”: “3306”,
“database.user”: “cdc_user”,
“database.password”: “password”,
“database.server.id”: “12345”,
“database.server.name”: “my-mysql-db”,
“table.whitelist”: “mydb.my_table”,
“database.history.kafka.bootstrap.servers”: “kafka:9092”,
“database.history.kafka.topic”: “schema-changes.mydb”
}
}
Step 3: Transform Data for AllegroGraph
Once CDC captures the changes, they need to be transformed into RDF triples for AllegroGraph. This transformation can be done with a custom service or using middleware like Kafka Streams or Flink.
For each relational database change:
- INSERT and UPDATE: Map the row data into RDF triples. For example, a change in a customer record might be converted as:
<https://example.com/customer/123> <http://example.com/hasName> “John Doe” .
<https://example.com/customer/123> <http://example.com/hasEmail> “[email protected]” .
- DELETE: Create a deletion process in AllegroGraph for the corresponding triples.
Step 4: Load Data into AllegroGraph
After the transformation, use AllegroGraph’s APIs (e.g., SPARQL Update or HTTP API) to insert the triples into the graph database. You can either:
- Directly connect to AllegroGraph via its RESTful API to load the transformed triples.
- Use a batch processing framework to load data in real-time or micro-batches.
An example of inserting RDF triples via HTTP in Python:
import requests
endpoint = ‘https://localhost:10035/repositories/myRepo/statements’
rdf_data = ”’
<https://example.com/customer/123> <http://example.com/hasName> “John Doe” .
<https://example.com/customer/123> <http://example.com/hasEmail> “[email protected]” .
”’
headers = {
‘Content-Type’: ‘application/x-turtle’,
}
response = requests.post(endpoint, headers=headers, data=rdf_data)
if response.status_code == 204:
print(“Data successfully inserted into AllegroGraph.”)
else:
print(f”Failed to insert data: {response.text}”)
Step 5: Monitor and Maintain the Pipeline
Once set up, monitor the pipeline to ensure changes in the relational database are captured and reflected in AllegroGraph in real time. Tools like Kafka Monitoring or Debezium UI can help track the CDC process.
Benefits of CDC with AllegroGraph:
- Real-Time Synchronization: Changes in the relational database are reflected immediately in AllegroGraph, enabling real-time querying and analysis.
- Graph Analytics: You can now leverage graph-based queries, relationships, and semantic reasoning in AllegroGraph on data that originated from relational databases.
- Historical Tracking: CDC can provide a time-based history of changes, enabling temporal querying in AllegroGraph.

